AI 不会引用它"读不懂"或"不敢信"的内容。
这是矿工鸟 GEO 实验室在过去 3 个月、通过矿工鸟 GEO 检测工具诊断超过 50 家企业官网后得到的核心结论。
样本口径(匿名聚合):
- 样本规模:50+ 企业官网(仅统计官网,不含第三方社媒账号)
- 时间窗口:2025-12-01 至 2026-02-28(按月滚动复测)
- 行业分布(脱敏汇总):企业服务 34%、制造/工业 26%、消费电子/家电 18%、教育/培训 12%、其他行业 10%
- 评测方法:40 条标准问句 × 6 大模型(豆包/元宝/文心/Kimi/DeepSeek/通义)进行批量复测
- 判定规则:统一记录引用率、引用位次、引用准确性;仅输出聚合结果,不披露客户名称、域名或可识别业务信息
这篇文章不短,但是值得你看完!
TL;DR
- GEO 可引用度衡量的是「被大模型引用的概率与质量」,不是传统 SEO 排名。
- 本文给出 5 层 23 维评分模型,用于评估企业官网的 AI 引用就绪度。
- 权重设计为:实体基础层 30%,内容理解层 25%,可信度层 25%,可发现性层 10%,监测与迭代层 10%。
- 总分是「就绪度」指标,不是结果承诺;需要用 6 大模型实测数据持续校准。
- 文末提供公开版 CSV 自查表,完整版评估细则可联系矿工鸟销售团队获取。
很多企业在做 GEO 优化时,面临一个共同问题:
"我们知道官网要做结构化数据、要写深度内容、要 build EEAT 信号,但怎么判断做完之后,AI 就真的更愿意引用我们了?"
现有的 SEO 评分工具回答不了新时代的 GEO 问题——因为它们优化的是"爬虫抓取效率"和"关键词排名",而不是"AI 理解与引用意愿"。
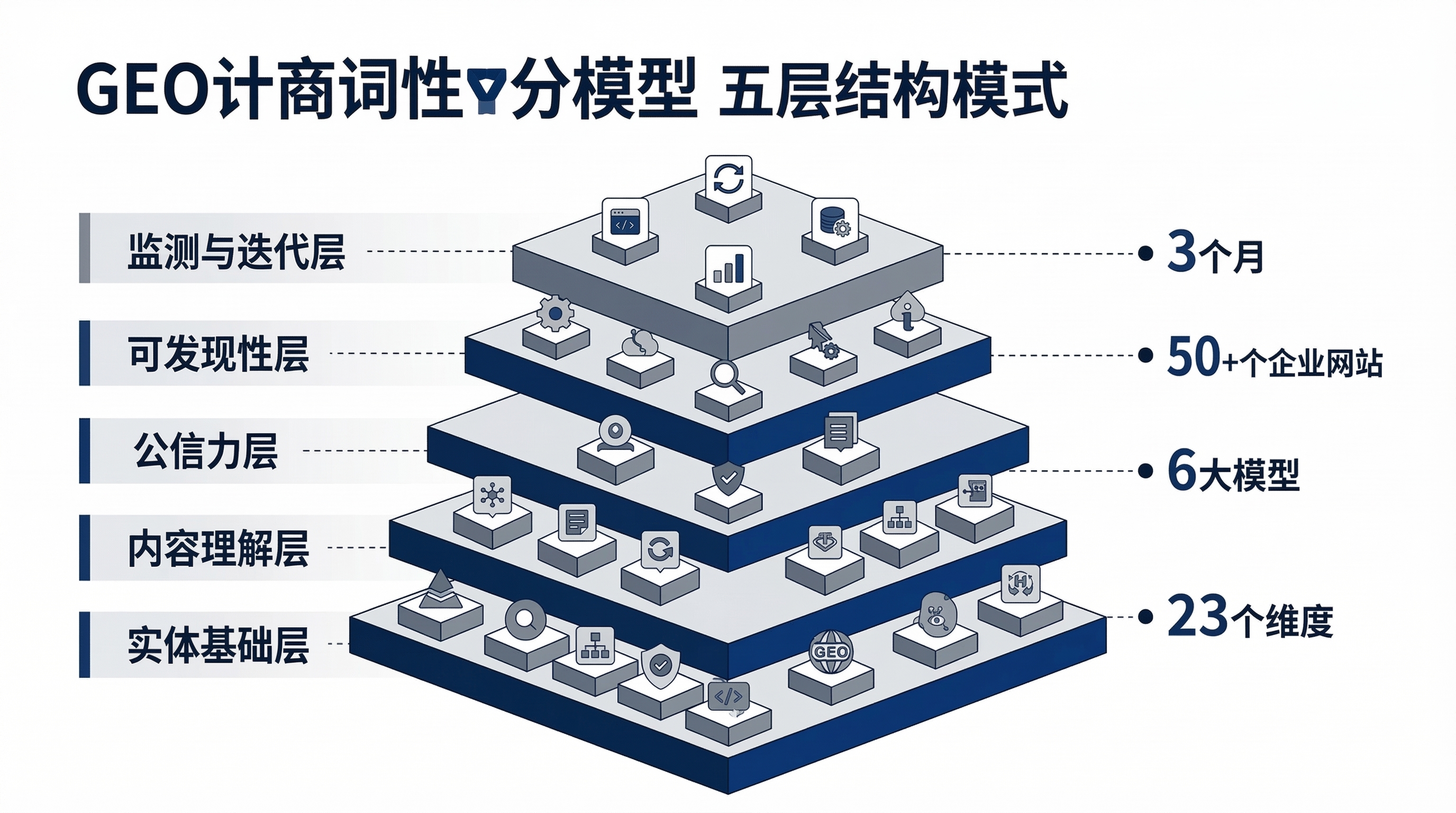
矿工鸟 GEO 实验室提出GEO 可引用度评分模型(GEO Citability Score),从 5 个层级、23 个维度系统评估网站被大模型引用的就绪度。
一、什么是"可引用度"
可引用度(Citability):指一个网站的内容被大模型在生成回答时主动引用为来源的概率与质量。
GEO 与 SEO 的主要差异:
| 维度 | SEO | GEO |
|---|---|---|
| 优化目标 | 排名第一 | 被准确引用 |
| 流量模式 | 点击流量 | 零点击引用 |
| 关键指标 | CTR、排名、流量 | 引用率、准确性、可信度 |
| 内容策略 | 关键词密度、外链 | 结构化、深度、可验证性 |
| 竞争方式 | 抢占排名 | 成为权威信源 |
核心判断:SEO 分数高的网站,GEO 可引用度不一定高。
一个页面可以靠外链和关键词优化排到第一,但内容本身缺乏结构化数据、没有明确的数据来源、缺少作者资质信息的话,AI 可不一定喜欢你!因为这些恰恰是 AI 判断"是否敢引用"的关键信号。
二、评分模型设计
2.1 5 层架构
模型基于 AI 处理信息的完整链路 5 层设计:
▶ AI 能否识别"你是谁"并稳定归因 → 实体基础层(30%)
▶ AI 能否准确理解你的内容 → 内容理解层(25%)
▶ AI 是否愿意引用你的内容 → 可信度层(25%)
▶ AI 能否在不同场景发现你 → 可发现性层(10%)
▶ 能否持续监测并迭代优化 → 监测与迭代层(10%)5 层链路的权重分配逻辑:
- 实体基础层(30%)权重最高:如果 AI 无法正确识别企业实体,后续所有内容都无法正确归因。
- 内容理解层与可信度层并重(各 25%):"读得懂"和"信得过"同等重要。
- 可发现性层(10%)权重较低:多语言、社交媒体等是"加分项",不是"必选项"。
- 监测与迭代层(10%):GEO 不是一次性工程,需要持续追踪。
2.2 23 维指标总表
| 层级 | 编号 | 维度名称 | 权重 | 评估项数量 |
|---|---|---|---|---|
| I. 实体基础层 | 30% | |||
| 1.1 | 结构化数据实现 | ⭐⭐⭐⭐⭐ | 7 | |
| 1.2 | 实体一致性与消歧 | ⭐⭐⭐⭐⭐ | 4 | |
| 1.3 | 知识图谱连接 | ⭐⭐⭐⭐ | 4 | |
| 1.4 | 语义化 HTML 与可访问性 | ⭐⭐⭐⭐ | 4 | |
| 1.5 | 技术 SEO 基础 | ⭐⭐⭐⭐ | 5 | |
| 1.6 | 站点性能与健康 | ⭐⭐⭐ | 3 | |
| II. 内容理解层 | 25% | |||
| 2.1 | 内容结构优化 | ⭐⭐⭐⭐⭐ | 4 | |
| 2.2 | 企业内容矩阵 | ⭐⭐⭐⭐⭐ | 5 | |
| 2.3 | 多模态内容优化 | ⭐⭐⭐⭐ | 3 | |
| 2.4 | 数据与信息密度 | ⭐⭐⭐⭐ | 3 | |
| III. 可信度层 | 25% | |||
| 3.1 | EEAT 信号 | ⭐⭐⭐⭐⭐ | 5 | |
| 3.2 | 内容可验证性 | ⭐⭐⭐⭐ | 3 | |
| 3.3 | 内容独特性与深度 | ⭐⭐⭐⭐ | 3 | |
| 3.4 | 用户生成内容(UGC) | ⭐⭐⭐ | 3 | |
| IV. 可发现性层 | 10% | |||
| 4.1 | 语言与国际化 | ⭐⭐⭐ | 3 | |
| 4.2 | 社交媒体优化(SMO) | ⭐⭐⭐ | 3 | |
| 4.3 | 内容分发 | ⭐⭐ | 2 | |
| V. 监测与迭代 | 10% | |||
| 5.1 | GEO 指标监测 | ⭐⭐⭐⭐ | 3 | |
| 5.2 | 竞品对比 | ⭐⭐⭐ | 4 | |
| 5.3 | 持续优化 | ⭐⭐⭐⭐ | 3 |
说明:
- ⭐⭐⭐⭐⭐ 核心维度,直接影响 AI 识别和引用
- ⭐⭐⭐⭐ 重要维度,显著影响引用质量
- ⭐⭐⭐ 基础维度,建议逐步完善
三、核心维度详解
3.1 结构化数据实现(1.1)
评估内容:
- Organization Schema(企业实体)是否完整
- WebSite Schema(站点元数据)是否部署
- BreadcrumbList(面包屑导航)是否结构化
- 业务相关 Schema(Product/Service/FAQPage/Article)覆盖度
- JSON-LD 格式优先(相比 Microdata 更易解析)
- Schema 关联关系(@id 跨页面引用)
- Google Rich Results Test 验证通过率
常见问题:
- Schema 只部署在首页,内页缺失
- Organization 信息在不同页面不一致
- 缺少 sameAs 链接到权威数据源
整改建议:
{
"@context": "https://schema.org",
"@type": "Organization",
"@id": "https://example.com/#organization",
"name": "企业名称",
"legalName": "企业法定名称",
"url": "https://example.com",
"logo": "https://example.com/logo.png",
"sameAs": [
"https://www.wikidata.org/wiki/Q123456",
"https://www.linkedin.com/company/example"
]
}3.2 实体一致性与消歧(1.2)
评估内容:
- @id 的全局唯一性(使用官网域名作为命名空间)
- 品牌名统一性(legalName vs name vs alternateName)
- sameAs 链接权威数据源(Wikidata/维基百科/Crunchbase)
- 跨页面实体一致性(联系方式/社交账号/品牌描述)
为什么重要: AI 在处理海量信息时,需要判断"这个页面提到的公司"和"那个页面提到的公司"是不是同一个实体。如果@id 不统一、品牌名写法不一致(中英文混用、简称全称混用),AI 可能无法正确归因,导致引用分散。
3.3 EEAT 信号落地(3.1)
评估内容:
- 专业性(Expertise):作者信息展示、专业资质/认证、行业经验说明、团队背景介绍
- 经验(Experience):一手数据/研究、实际案例、产品使用记录、客户评价
- 权威性(Authoritativeness):行业奖项/认证、媒体报道、合作伙伴、权威机构背书
- 可信度(Trustworthiness):完整联系方式、隐私政策/服务条款、客户服务渠道、公司注册信息、SSL 证书
核心金句:
"AI 不会引用它无法验证的内容。EEAT 信号的本质,是给 AI 提供'敢于引用'的理由。"
常见问题:
- 博客文章没有作者信息
- 案例研究缺少客户名称和量化结果
- 联系方式只有表单,没有电话/地址
3.4 内容结构优化(2.1)
AI 友好的内容形态:
- 列表(有序/无序)
- 表格(对比数据)
- 步骤说明(操作指南)
- 问答对(FAQ)
- 定义列表(术语解释)
内容组织模式:
- 倒金字塔(结论前置)
- TL;DR 摘要(80-100 字)
- 章节目录(
nav+ TOC) - 关键信息高亮
为什么有效: 大模型在抽取信息时,偏好结构化、边界清晰的内容块。一段 500 字的连续文本,不如 5 个要点列表容易被抽取和引用。
四、评分计算方法
4.1 单项得分公式
单项得分 = (已实现评估项 / 总评估项) × 100示例:结构化数据实现(1.1)共 7 个评估项,企业实现了 5 项:
单项得分 = (5 / 7) × 100 = 71.4 分4.2 层级得分公式
层级得分 = Σ(单项得分 × 单项权重)示例:实体基础层包含 6 个维度,各维度权重相等:
实体基础层得分 = (1.1 得分 + 1.2 得分 + ... + 1.6 得分) / 64.3 总分公式
GEO 可引用度总分 = Σ(层级得分 × 层级权重)总分 = 实体基础层得分 × 30% + 内容理解层得分 × 25% +
可信度层得分 × 25% + 可发现性层得分 × 10% +
监测与迭代层得分 × 10%4.4 等级划分
| 分数段 | 等级 | 说明 | 引用表现预测 |
|---|---|---|---|
| 90-100 | S | 高度可引用 | 6 大模型引用率>60% |
| 80-89 | A | 可引用,少量优化 | 引用率 40-60% |
| 70-79 | B | 基础就绪,需结构性整改 | 引用率 20-40% |
| 60-69 | C | 存在明显短板 | 引用率 10-20% |
| 0-59 | D | 不可引用状态 | 引用率小于 10% |
说明:引用率 = 品牌相关问句中被引用的次数 / 总查询次数
五、校准方法
评分模型的预测是否准确,需要通过实际 AI 引用表现来验证。
5.1 人工复测校准
人工复测校准步骤:
- 设计 40 条标准问句(品牌核心、购买决策、竞品对比、通用行业)
- 在 6 大模型(豆包/元宝/文心/Kimi/DeepSeek/通义)中分别查询(如果您想更快、更有效率的查询,当然要使用矿工鸟提供的监控工具了)
- 统计引用率、引用位置、引用准确性
- 对比评分预测与实际表现
校准规则:
- 如果评分 S 级但实际引用率<40% → 检查权重是否高估了某些维度
- 如果评分 B 级但实际引用率>50% → 检查是否有未纳入的加分因素
5.2 竞品对标校准
步骤:
- 选择 3-5 个同行业竞品
- 分别计算 GEO 可引用度评分
- 对比评分差异与引用表现差异
- 调整权重以匹配实际观察
示例:
本品牌评分 75 分,竞品 A 评分 82 分
实测引用率:本品牌 35%,竞品 A 45%
→ 评分差异与表现差异一致,权重合理
本品牌评分 75 分,竞品 B 评分 70 分
实测引用率:本品牌 35%,竞品 B 50%
→ 评分与表现倒挂,需重新评估权重5.3 时间维度校准
建议:
- 大模型每季度至少迭代一次,引用策略可能变化
- 建议企业季度复评一次 GEO 可引用度
- 建立历史版本档案,追踪优化效果
六、本文章局限性
- 行业差异:医疗、金融等强监管行业需调整权重
- 多语言站点:当前模型主要针对中文站点
- 非官网渠道:仅评估企业官网,社交媒体需独立评估
- 模型版本迭代:不同大模型引用策略存在差异
七、FAQ
Q1: 评分多久更新一次?
建议企业每个季度复评一次。如果期间进行了大规模网站改版或内容重构,可在完成后立即复评。
Q2: 评分高是否等于一定被引用?
不一定。评分衡量的是"就绪度",实际引用还受竞争格局、问句类型、模型版本等因素影响。但评分高是必要条件。
Q3: 如何获取完整评估表?
我们提供完整的 23 维评估表(Excel/CSV 格式),包含每个维度的详细评估项、打分标准、整改建议,您可以通过联系我们的销售人员获得。
八、附录(公开版)
8.1 23 维评估表(CSV,公开版)
说明:公开版用于企业自查。若需要包含分项打分细则、整改优先级与行业定制权重的完整版,请联系销售团队获取。
8.3 推荐验证工具清单
- 矿工鸟 GEO 监测工具:用于 6 大模型批量复测,跟踪引用率、引用位次与引用准确性
- Google Rich Results Test:验证 Schema 结构化数据
- Schema.org Validator:验证 Schema 语法
- PageSpeed Insights:评估 Core Web Vitals
- WAVE:评估可访问性
- Ahrefs/SEMrush:评估技术 SEO 基础
作者:矿工鸟 GEO 实验室
版本:V1.0(2026-03)